
Overview
Apache Beam is a unified programming model and the name Beam means Batch + strEAM. It is good at processing both batch and streaming data and can be run on different runners, such as Google Dataflow, Apache Spark, and Apache Flink. The Beam programming guide documents on how to develop a pipeline and the WordCount demonstrates an example. Please refer to these materials if you are not familiar with basic concepts. This article focuses on writing and deploying a beam pipeline to read a CSV file and write to Parquet on Google Dataflow.
Design
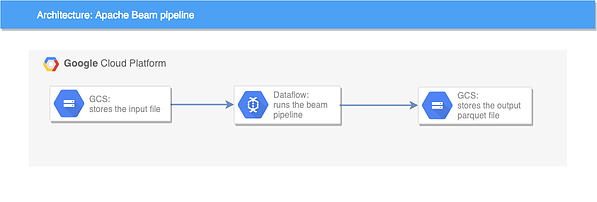
The following diagram shows the logical architecture of the application. The input CSV file and the output parquet files are stored on GCS (Google Cloud Storage), while the actual data processing are run on Dataflow.
Implementation
Step 1: Create a pipeline which takes in command-line parameters.
Options options = PipelineOptionsFactory.fromArgs(args).withValidation().as(Options.class);
Pipeline p = Pipeline.create(options);
Step 2: Implement the Options interface.
public interface Options extends PipelineOptions {
@Description("Input file path")
@Validation.Required
String getInputFile();
void setInputFile(String value);
@Description("Output directory")
@Validation.Required
String getOutputDir();
void setOutputDir(String value);
}
Step 3: Read and parse the input file.
p.apply(FileIO.match().filepattern(options.getInputFile())) //PCollection<Metadata>
.apply(FileIO.readMatches()) //PCollection<ReadableFile>
.apply(ParDo.of(new CsvParser())) //PCollection<CSVRecord>
The CsvParser code is as followed. Manually using a delimiter to split fields can result in issues because some text fields might contain the delimiter. So a proper CSV parser library, Apache Commons CSV is used.
@DoFn.ProcessElement
public void processElement(@Element ReadableFile element, DoFn.OutputReceiver<CSVRecord> receiver) throws IOException {
InputStream is = Channels.newInputStream(element.open());
Reader reader = new InputStreamReader(is);
Iterable<CSVRecord> records = CSVFormat.DEFAULT.withHeader(headerNames).withDelimiter(delimiter).withFirstRecordAsHeader().parse(reader);
for (CSVRecord record : records) { receiver.output(record); }
}
Step 4: Convert CSV record to Parquet record.
In this step, we convert every CSV record to Generic record using an AVRO schema.
@DoFn.ProcessElement
public void processElement(@Element CSVRecord element, DoFn.OutputReceiver<GenericRecord> receiver) {
GenericRecord genericRecord = new GenericData.Record(schema);
List<Schema.Field> fields = schema.getFields();
for (Schema.Field field : fields) {
String fieldType = field.schema().getType().getName().toLowerCase();
switch (fieldType) {
case "string":
genericRecord.put(field.name(), element.get(field.name().toUpperCase()));
break;
case "int":
genericRecord.put(field.name(), Integer.valueOf(element.get(field.name().toUpperCase())));
break;
case "long":
genericRecord.put(field.name(), Long.valueOf(element.get(field.name().toUpperCase())));
break;
default:
throw new IllegalArgumentException("Field type " + fieldType + " is not supported.");
}
}
receiver.output(genericRecord);
}
Step 5: Write to Parquet.
The final step is to write Parquet to GCS. The whole pipeline looks like this:
p.apply(FileIO.match().filepattern(options.getInputFile())) //PCollection<Metadata>
.apply(FileIO.readMatches()) //PCollection<ReadableFile>
.apply(ParDo.of(new CsvParser())) //PCollection<CSVRecord>
.apply("Convert CSV to parquet", ParDo.of(new ConvertCsvToParquet(schema.toString()))) //PCollection<GenericRecord>
.setCoder(AvroCoder.of(GenericRecord.class, schema)) //PCollection<GenericRecord>
.apply(FileIO.<GenericRecord>write().via(ParquetIO.sink(schema)).to(options.getOutput()).withSuffix(".parquet"));
Step 6: Run the pipeline on Dataflow.
mvn compile exec:java \
-Dexec.mainClass=your.class \
-Pdataflow-runner -Dexec.args=" \
--project=your-project \
--stagingLocation=gs://your-bucket/staging/ \
--runner=DataflowRunner \
--inputFile=gs://your-bucket/resources/test.csv \
--outputDir=gs://your-bucket/test-output/"Lessons Learned
This article shows how to write and deploy an Apache Beam pipeline on Dataflow. I used FileIO to read the input CSV file. But initially, I tried to read in the file first using
Iterable<CSVRecord> records = ...
Then I passed the records object into the Create.of() function provided by Beam.
p.apply(Create.of(records))
However, it didn't pass any element to the next ParDo function, which was a bit tricky!
After testing a few pipelines with Beam and Dataflow, I personally like the combination as both batch and streaming data can be processed in the same Dataflow job (Not included in this article though, but you can try it out)! When it comes to this use case, I would highly recommend using Beam to process your data! But writing a Beam pipeline does involve a bit coding so if you don't like coding, StreamSets might be a better choice!
That's it. Hope you enjoy the article and get your hands on to code your own pipelines!
