
Overview
Apache Kafka allows both local and cloud deployment so you can publish data from on premise environment and trigger services in the cloud. It is at the heart of our stacks that require real time processing. Confluent KSQL (streaming engine) allows stream processing in a simple and interactive SQL interface for processing data in Kafka in a distributed, scalable and reliable fashion. It interacts directly with Kafka Streams API, saving the need to develop a separate application to do so. KSQL is further supported by a range of streaming operations such as joins, aggregation and counts etc. Typically, in a local environment, 8088 is the default port used by KSQL.
In one of the recent projects at Deloitte Platform Engineering, where we are leveraging Apache Kafka’s capability, the development team required to access KSQL locally from the Confluent Apache Kafka hosted in a secure GKE (Google Kubernetes Engine) cluster to perform streaming operations and execute KSQL queries.
BEFORE YOU BEGIN
- Install kubefwd which is an open source utility that allows you to develop applications locally while in sync with other services in your Kubernetes cluster. It has been designed to port forward selective or all pods within Kubernetes namespaces. This provides an effective way to do development on your local machine and interact with the Kubernetes cluster. You can read more about kubefwd in this blog post by Craig Johnston: https://imti.co/kubernetes-port-forwarding/ and check out the Github: https://github.com/txn2/kubefwd
- Download Confluent Platform on your local machine (this is to provide you with KSQL CLI) on your localhost: https://www.confluent.io/download/
- Install gcloud, command line interface to provide you with primary CLI to GCP (Google Cloud Platform). For detailed intructions on installing gcloud, please see: https://cloud.google.com/sdk/install
- Install kubectl, it is a command line interface which enables you to run commands on your Kubernetes cluster. You can read more about kubectl on: https://kubernetes.io/docs/reference/kubectl/kubectl/ For detail installation instructions please see: https://kubernetes.io/docs/tasks/tools/install-kubectl/
HERE ARE THE STEPS
1. Log into the GKE cluster you want to connect to
gcloud beta container clusters get-credentials kube-cluster-name --region some-region --project some-project
The command above will allow you to connect to your project in the Kubernetes cluster. This will also update your kubeconfig file with access credentials and endpoint information to point kubectl to the desired cluster in GKE (Google Kubernetes Engine).
2. Validate you can connect to kube control plan
kubectl get svc
The command above will list all the services running in your cluster. Other commands that kubectl allows can be found in this cheat sheet: https://gist.github.com/DanielBerman/0724195d977f97d68fc2c7bc4a4e0419
3. Run kubefwd
sudo kubefwd services -n namespace
This command will forward all the services running within your specified namespace to local workstation.
4. Determine the url for ksql-server from the following command.
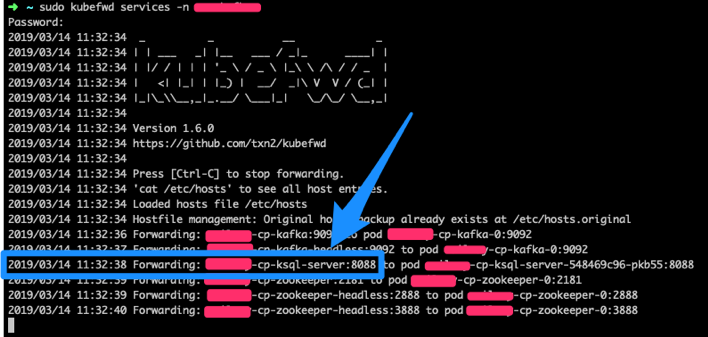
In our case it was: http://projectname-cp-ksql-server:8088/info
Note: kubefwd adds entries into your /etc/hosts file so you can access the services locally using the service name.
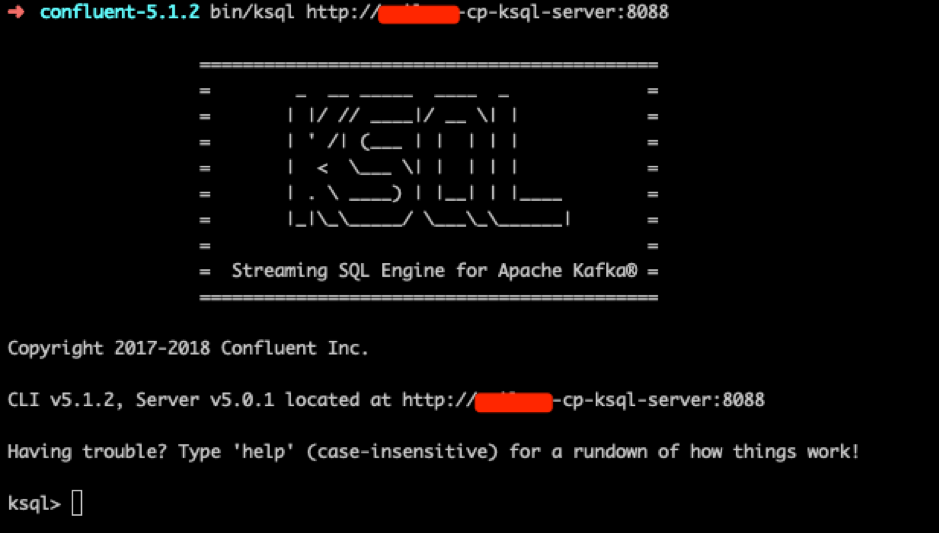
5. From your CLI launch confluent-5.1.2/bin/ksql http://your-url:8088 to execute queries.
In our case it was: confluent-5.1.2 bin/ksql http://projectname-cp-ksql-server:8088
And, you should see similar output:
Wrapping Up
The blog post is just one of the many possible applications of kubefwd and KSQL’s scalability. The steps above can be interpreted to access some other service in your Kubernetes cluster from your localhost. If you find an alternative and/or more efficient methods, please let us know in the comments below. Happy port forwarding!