
 This article is co-written with Robert Li
This article is co-written with Robert Li
Robert is a Lead in the Data Team at AMP Capital.
He is passionate about building data and analytics applications that empower people to do their best work.
What this article is not
We love dbt and believe it is a great tool to manage your data transformation. This article is all about why and how. This is not an introductory article; you need a basic understanding of containers and serverless architecture. In addition to that, you should be familiar with dbt and preferably try the dbt tutorial. If not please bookmark this post and come back later.
.jpg?width=1280&name=h-shaw-yty30exygSI-unsplash%20(3).jpg)
Why we love dbt
If you read the dbt Viewpoint and start nodding more and more as you go, then dbt is for you. In the data pipeline, we must capture business logic to give the data meaning.
If the data and business logic is maintained by the business units, then the relevance and meaning is rich, but it’s probably disorganised, badly tested, and inconsistently documented.
If it was put together by an IT function, then it was probably relevant 5 years ago, but since then there has been no funding. Neither scenario will allow the business to gain valuable insights that enable reaction to change.
We believe that giving data meaning is fundamentally an analytics function which is best done by the business. We also believe analytics is best achieved through code. We love dbt because it’s a tool aimed at the business data analyst who codes:
- dbt’s SQL heritage presents an already familiar language which data analysts can use to explore deep into the warehouse. Most importantly, it allows them to express their business logic within a tested and well documented framework.
- Coding brings many benefits. Coding best practices address complexity, distributed working patterns, and a merging of many people’s work into one source of truth. This expectation allows for scalability across teams and beyond generations of people in an organisation.
This powerful combo means dbt allows the business to explore and experiment, enables complexity to scale elegantly, and provides automation via mature CICD practices and tools.
Why serverless fits with dbt
Here is why dbt is a great fit to this microservices/serverless world we live in:
- dbt does not need to know the state of the previously run execution as it won't necessarily impact it; everything including state is stored in the database.
- All you need to execute dbt besides a running database is your SQL code, the dbt libraries and and dbt packages.
- dbt doesn't need heaps of memory or CPU power and with modern data warehouses the computation happens on the db side anyway.
In order to support dbt, your solution will need:
- a running environment which is only available for the duration of the execution.
- quick bootstrapping (minutes is ok) to minimise the latency added to each dbt execution.
- ability to run Python.
- ability to pull the latest dbt models (your project code).
- orchestration capabilities to run different commands.
Serverless architecture will give us just that.
Building your dbt project
We recommend starting with the default structure created by the dbt init [TD1] command and checking out the best practices from the folks at dbt (dbt documentation, dbt app reference, and discourse).
Some features of dbt that we like:
- Packaging which allows you to easily share and re-use code.
- Schema configuration which allows you to only show what you want to whom you want
- The dbt seed function which allows data to live with the source code and be materialised in the database for use downstream.
- We think this works well for mapping categories, or listing constants like timetables, important dates, or KPIs.
- Be careful this is not a backdoor into your data warehouse that will lead to governance and scaling issues. But let’s be real, important data lives in spreadsheets! A dedicated sheet-loading pipeline for this use case is better.
- Testing, table lineage, and documentation out of the box which supports data governance – something we believe to be a fundamental requirement.
- The custom metadata feature which allows you to create structured metadata while writing your SQL. dbt then compiles all of this into its manifest.json file which allows you to ETL the metadata into your enterprise tool (or anywhere really). You can also use this metadata to do cool things like find all columns to mask. [TD1]
- Hooks which allow any SQL to be executed before or after a dbt run. We use it for granting access and adding keys to tables.
Configuring your dbt environment
dbt allows flexible project configuration. It can be done globally at the project level, and all the way down to the model level. It is well documented and follows logical inheritance patterns.
We will highlight just one important feature: environment variables.
Your dbt project exists in a broader data platform ecosystem. Therefore, it needs to inter-operate with all your other components - particularly in a serverless architecture. We use environment variables in our dbt project to configure the project for the given environment.
Some benefits of this approach:
- We can ensure references to databases, schemas, usernames, etc are variables so that they can dynamically change as dbt is promoted through each execution environment.
- We can use Jinja macros in dbt to change the SQL based on the environment. For example, in development we minimise how many records are transformed - saving time and compute resources.
Designing dbt for a serverless architecture
Before we start it is worth mentioning that dbt works well with ELT pattern, where your data is extracted (“E”) and loaded (“L”) into your warehouse separately and then dbt does the transform (“T”) for you. Your data will be extracted from different sources and loaded into your data warehouse which will then trigger dbt serverless to perform the necessary transformation and tests.
The following diagram shows the overall architecture of an ELT pipeline with dbt.
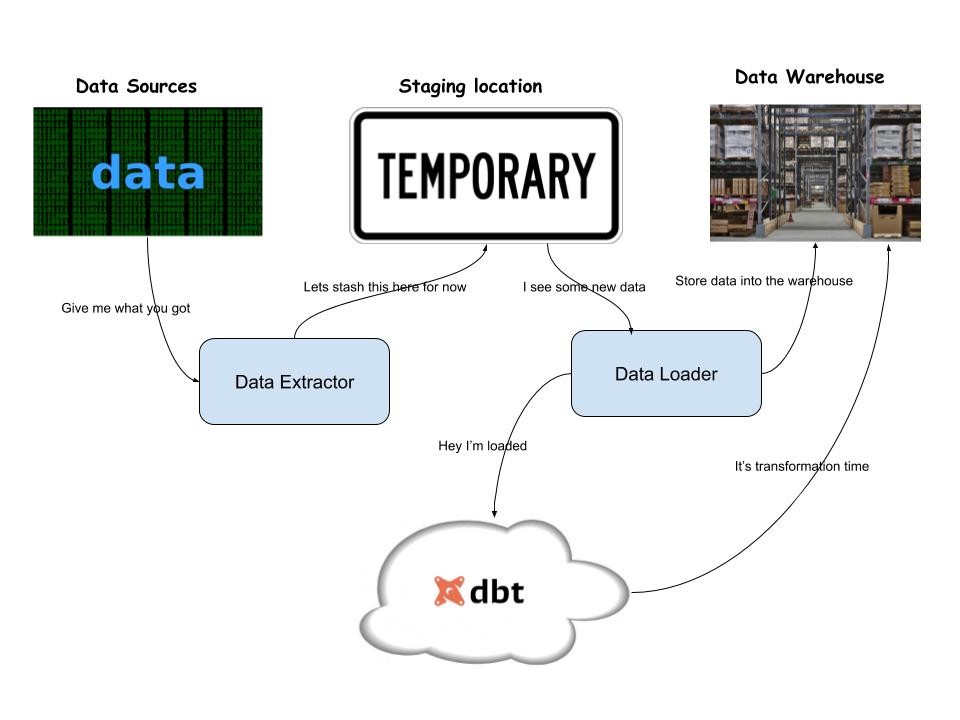
dbt serverless is a process that orchestrates running dbt models against your warehouse. The design is based on AWS services but it can be implemented in any of the other cloud provider services. The services you will need are:
|
Service |
Function |
Examples of products |
|
Orchestration service |
Manages the dbt life cycle |
Airflow, AWS Step Functions |
|
Container management service |
Runs your dbt models on demand |
|
|
Code repo |
Versions control your dbt project (models, docs, tests) |
GitHub, Bitbucket, GitLab |
|
Container Registry |
Hosts your dbt docker images (dbt + models) |
AWS ECR, Docker Hub |
|
Build / CICD server |
Builds a new dbt image that contains the latest dbt models and push that to the container registry |
Jenkins |
|
Static web host |
Hosts the dbt documentation portal |
Amazon S3 |
The following diagram shows how the above services can be tied together:
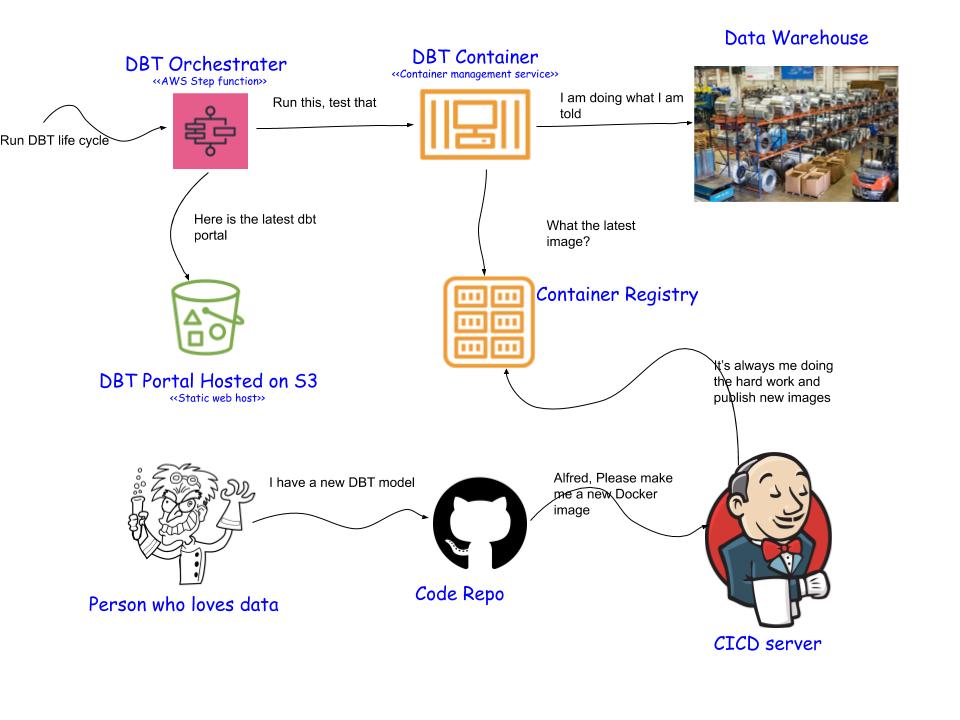
At the heart of this solution is your dbt project, it will be packaged into a Docker image (your latest models + dbt lib) and published to your container registry ready to be executed on demand. This enables you to create an Elastic Container Service (ECS) task that refers to your latest dbt image which will then be started by the step function whenever required. The dbt image needs to be updated whenever your model changes to make sure that each time dbt runs it executes the latest code.
Regardless of how you load your data, once a new batch is loaded you need to notify dbt serverless (or schedule it to run after your batch loading routine) to make sure that your staging data is updated.
Orchestrating your dbt runs
The orchestrator orchestrates (ha!) the dbt life cycle and it can be triggered:
- whenever a new data set is loaded.
- on a schedule to meet a business requirement or for QA purposes.
- whenever a new dbt model is published.
The orchestrator can perform the following steps:
- Runs dbt latest models which transforms the data
- Tests the latest state of your data to validate that the new models/data sets haven’t introduced inconsistencies.
- Generates your project docs and publish it.
Some notes regarding the above process:
- Try to execute only models related to either newly loaded data or the latest published models, to minimise the dbt running time. This can be achieved by tagging the models and model execution syntax.
- The orchestrator can run in a full refresh mode to execute all models if you want to rebuild your whole DWH from existing RAW tables.
- When your run fails, consider retrying by running a dbt full refresh to manage any model dependencies.
- dbt doesn’t support roll-back as it runs directly in your database. As a workaround, you can introduce a temporary staging location to execute your dbt model and validate it before copying the data across to your permanent location; then run your dbt models again.
Summary
In this article we talked about dbt and how to build a serverless platform around it. There are other aspects that we haven’t talked about which can be covered in future articles, for example:
- How to build a modern engineering pipeline for your dbt projects.
- dbt rollback solution following the blue/green deployment model.
- How to build QA around your dbt projects.
We encourage you to consider dbt for your enterprise data transformation tasks wherever you need version control, automated testing, and dynamic documentation generation.
References
dbt Serverless starter project includes Step function code and supporting infrastructure.
Starter project from executing dbt init command.
Mature project that diverges majorly from the basic structure.