
 When Deloitte Platform Engineering teams start on a new client, we bring with us our development processes that help deliver value.
When Deloitte Platform Engineering teams start on a new client, we bring with us our development processes that help deliver value.
These processes continuously improve as they are applied to many, many engagements and evolve as trends and industry consensus change. This means that we can have all the maturity that comes with establishing a new development team that normally takes many months, in a matter of days.
One of the first questions I am often asked is "what branching strategy should we use?". This is a valid question but, in my opinion, hardly the first one we should answer.
The way we work and the way we release products define the branching strategy. Not the other way around.
It is to my eternal frustration when defining release management processes is deferred till much later in the project, because "production release is months away". And when the time comes, so does the rapid realisation that the branching strategy chosen without foresight somehow does not match up with the release management aspirations.
I find it equally frustrating when teams try to strive for excruciatingly generic processes, rather than spending the time gathering requirements and understanding what is needed. If we are building, say a set of microservices, then why not design a process that makes our most frequent use case as frictionless as possible?
Keeping the microservices theme, in this post, I'd like to lay out what I consider to be an optimal approach to branching strategies, CI/CD and release (which I collectively call "Development Workflow") when delivering microservices.
For the impatient, you can jump down to The Patterns chapter to see what this looks like. The intervening chapters will discuss the why before we get to the how. And as a developer, I can tell you that I will not buy into process unless I know why I am doing it.
Parameters
Designing processes in a vacuum is a good way of coming up with something truly terrible. So instead let us define some guardrails to give us focus as we solution.
For this, I have come up with an imaginary new engagement and defined some hypothetical requirements.
|
Requirement |
Description |
|
Git |
Git is the most popular source code management system out there and we use it every time we get the choice. While I don't expect developers to be Git experts, they should know Git, as well as a tradie should know their hammer |
|
Microservices architecture |
We will focus on microservices (see below for details). This process may not be suitable for, say, front-end development without modification. |
|
Multiple repos |
Each microservice will reside in its own Git repository, as opposed to a mono-repo for all of them. This is assumed for my imaginary project but some discussion around this topic can be found below. |
|
Target containerised platforms |
Let's assume the runtime for this project is a containerised platform, such as the many flavours of Kubernetes. This requirement does not significantly affect the process we will define, however it allows us to apply the process to any technology stack. |
|
Commercial setting |
This is as opposed to an "open source" setting. In a commercial setting, we tend to know all the developers that will be contributing code and there is an expectation for a higher level of quality output from dedicated developers. |
|
Smaller, more frequent releases |
Following the modern trends of DevOps and CI/CD, this project leans towards a shorter feedback loop, rather than risky big-bang releases. |
|
Parallel feature development |
The essential component of a successful workflow is to allow multiple developers to deliver features on the same piece of code. Our process should make this as easy as possible. |
|
Hotfix development |
The defined workflow should allow delivering hotfix for critical production defects. This should be possible even if work on a new release has begun and the source code has moved on. |
|
Parallel release development |
Timelines and roadmap sometimes will demand features to be developed that are targeted for different releases. This should be possible to do in our workflow. |
|
Parallel major versions in production |
New major versions are an unavoidable fact of life as products evolve. However, it is not always practical to expect all consumers to move to the new major version right away. So our workflow should allow for the old and new version to co-exist in production, at least as long as it takes to migrate all consumers over. |
In addition to those requirements, there are also some less imaginary best practices, that I normally like to see in one such process:
|
Best Practice |
Description |
|
Intuitive and unambiguous |
This requirement, ironically, sounds vague and ambiguous. It is not something we can measure easily and it is more of an art than science. However, I am of the firm belief that a human process needs to be elegant: a simple set of rules/patterns with very few exceptions. |
|
Reduce ceremonies |
Whenever you find yourself doing a task but cannot help but keep asking yourself what is its purposes, you are doing some ceremony. A menial task that may have held some meaning in the past or is required just in case of some rare occurrence. Ceremonies are a hallmark of a poorly thought-out process. They provide little value and waste developer time, who are pathologically impatient and lazy already. A process should be like a samurai pulling out his katana: no unnecessary movement or flourishes, only efficient and calculated movements all in the service of the outcome. Reducing ceremonies becomes particularly important as they tend to repeat and multiply with the number of your repos and we will have many. |
|
Minimise long-living branches |
I find this tweet distils why this is important. Think of long-living branches as a multi-master data synchronisation problem. I don't have to tell you that is not an easy problem to solve, especially when it has to be done manually by developers. Please have mercy on your developers! |
|
Build in quality |
This is increasingly being called "shifting left". It is common wisdom that you want to catch any issues as early as possible in the process. To this end, the workflow should include mechanisms to measure and gate quality, be it functional, security or otherwise. |
|
Build binaries once |
Modern CI/CD processes favour "build once, deploy many times" model. This helps to increase confidence in the process and the subsequent production deployment as we are sure that the same immutable artifact has been promoted through the various environments and it has gone through the various quality assurance exercises. The rise of containerisation has made this an attractive feature of any respectable pipeline. We package the application once in a container image and then it is promoted as desired. |
As the years have gone by, it is becoming rarer that I need to argue about some of the above points. What was once considered controversial is now common wisdom. That said, I would like to expand on a few topics below.
On Microservices Architecture
We have written extensively about microservices in this blog so I will keep things light here. In the context of this post, the following characteristics of a microservices architecture are relevant:
- Domain decomposition, which results in multiple services as independently deployable units with runtime dependencies to each other and downstream systems
- Decentralisation of data and governance along domain lines
- Extensive automation to flatten the overhead of dealing with many, many microservices
On Multiple Git Repos
Mono-repos and multi-repos are both perfectly valid options depending on what you are trying to do.
In a mono-repo setup, all applications are located in the same Git repository. We find this useful when we would want to:
- Treat the entire set of applications as a baseline to be versioned and deployed together
- Give more weight to build-time dependencies, over runtime ones
- Use CI/CD tooling and practices that can support mono-repos well
- Know that building the entire repo does not take an excessively long time
- Have developers who are Git savvy enough to handle frequent merge conflicts and other Git gymnastics
Things get ugly when you try to use mono-repos and treat each application separately, as preferred by microservices architecture. CI/CD needs to map from one repo to many pipelines. It is not plain what versions of each application exist in a given commit, let alone trying to tag the commit with versions. Having to examine the Git diff to understand the incoming changes gets old very fast.
Looking back at our requirements above, one repo per application makes much more sense. The main branch in each repo will track a single application unambiguously. Git tags can signal clearly what version exists within a commit.
Another oft-forgotten benefit of multiple repos is that changes are spread across them. This reduces how many developers are working within a single repo at the same time. There is less chance of complicated merge conflicts and it is rare for developers needing to reach for the more advanced Git commands.
I should note I have encountered some misconceptions when promoting multiple repos in organisations with a legacy development environment. We have to remember we are talking to developers, who have been scarred with a lot of menial and manual tasks in their career and normally in a single repo. To them trying to multiply this out to many repositories would seem daunting, if not impossible.
My approach is to remind them that things have drastically changed and improved in the industry. Much of the heavy lifting has been moved to CI/CD and automation. Adding each additional repository barely moves the needle when it comes to overheads. And there are certainly fewer headaches than when 20 people are working in the same repository.
On Shorter Releases
I hope it is quite intuitive why we prefer smaller and more frequent releases.
When the releases are larger and less frequent, each production release carries a much greater risk. The deployments take longer and require larger deployment windows. There are too many moving parts and triaging issues need to cover a lot of ground. Not to mention, the feedback loop to the QA team, business and end-users, is much longer, which will make no one happy. It is then no surprise that continuous delivery and DevOps principles have gained such foothold in modern engineering practices.
It should be noted that frequent releases cannot be achieved off the bat. As an organisation matures, it develops higher levels of quality assurance, automation and streamlined release management which unlocks this capability.
We normally treat the size of a release as a dial, turning it down as the maturity increases.

Path to Production
Understanding the CI/CD process is essential in determining how code changes should be delivered.
Targeting a runtime environment, such as Kubernetes, means that the output of our build process is a container image. This is a logical hand-off point between the build and deployment process. By versioning the resulting container image, we can use it to deploy to each environment thus, satisfying "build once, deploy many times" practice.
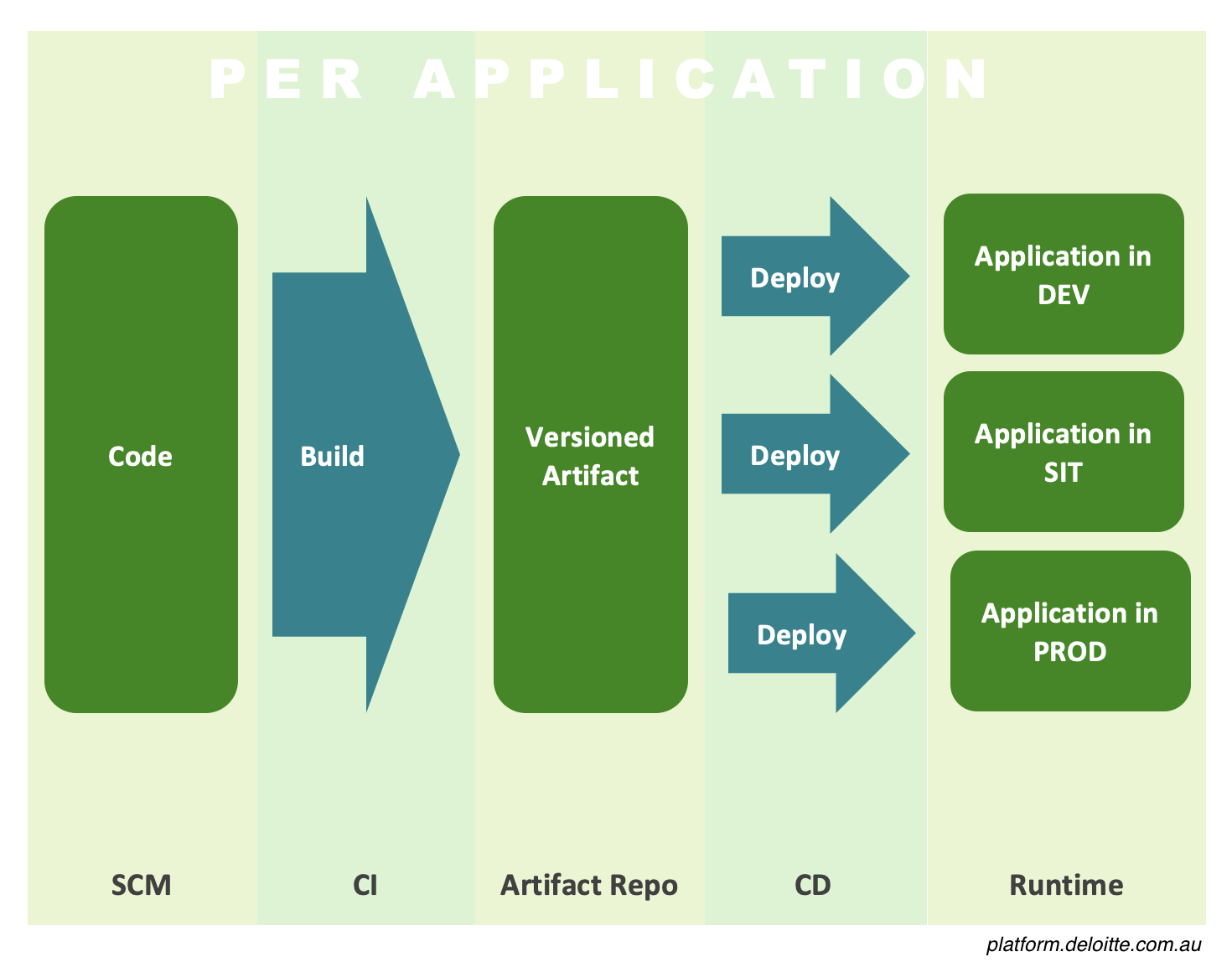
Most modern processes, like above, use different specialised tools to fulfil each stage of the pipeline. This is a far cry from the old school processes where SCM is dragged (kicking and screaming), throughout the workflow and used to track or trigger environment deployments, etc.

Versioning
An important part of this overall developer workflow is the way an application is versioned.
In the case of microservices, they naturally provide interfaces, such as APIs. These are then consumed by other microservices or upstream systems. This makes consumers an important component of managing a microservice's interface and driving some of the decisions made when versioning that interface.
Here are some of the versioning schemes that you may encounter in the wild:
|
Scheme
|
Examples
|
Supports Backward Compatibility
|
Supports Consumer Rollback
|
|
Static Versioning
|
latest
stable
next
|
🚫 | 🚫 |
|
Incremental Versioning
|
1
34
|
🚫 | ✅ |
|
Temporal Versioning
|
2021-1.3
20210423-4
|
🚫 | ✅ |
|
Semantic Versioning (semver)
|
1.2.11
3.0.0
|
✅ | ✅ |
|
Pre-Release Semantic Versioning
|
3.0.0-alpha-3
1.2.0-next.12
|
✅ | ✅ |
Static versioning uses a mutable version, which may sound blasphemous. However, it is ideal for those situations where the consumers are happy to be upgraded to the latest version without their consent.
Incremental versioning provides slightly more information as you can distinguish different versions but you cannot glean any more than that.
Temporal versioning is a nice fit for organisations with seasonal releases. IntelliJ IDEA is an example of this where they do quarterly major releases. But similar to incremental versioning, the versions do not provide a whole lot of information about what is contained within.
Semantic versioning is where things get interesting. It can unambiguously signal the nature of changes between two different versions. This allows consumers to make an informed decision on whether they can readily upgrade to the new version or if additional work is required.
In the fast-paced world of modern engineering, it is common to create a new version following each successful build, treating each as a release candidate. While these applications move through environments, bugs may be encountered so further builds and versions will occur. Commonly, some of these intervening versions will never make it to production.
This is a perfectly fine scheme for projects where most of the APIs are internal. What is important is comparing the existing production versions with the incoming one to understand the breadth of incoming changes.
However, this may be less desired for public APIs, where consumers may wonder what the heck happened to a specific version. Imagine if Spring released v10.0.0 when the last public release was v5.5.3. For these use cases, it may be desired to hold the changes and only release the whole lot to production when ready.
Pre-release extension to semantic versioning makes this possible. Each application can have one or more pre-release stages, indicated by a number or a codename, such as alpha/beta. Given that minor and patch versions are already backward compatible, pre-releases are most commonly used for major versions.
Maven veterans may now be feeling some twangs of familiarity here. SNAPSHOT versions are an example of pre-release versioning.
It should be obvious that there is slightly more planning and effort involved in pre-releases so this needs to be taken into consideration when deciding between the two schemes. That said, you are free to pre-release any version, including fixes, if it can be justified.
If you are curious about how you would implement semantic versioning in an automated manner, you may find my other post, Semantic Versioning using Conventional Commits, of interest.
The Patterns
Let's finally talk about how we are going to do our branching. A strategy is nothing but a set of patterns that can be applied repeatedly. The fewer patterns you have, the more elegant the resulting process.
Here are the patterns that we will apply to our branching strategy. Hopefully, many of these look very familiar.
Mainline Branching
One or more branches are used as the stable, source of truth for the repository. All other branches diverge and later converge back to these. It is also called Trunk Branching, a hangover from the SVN days.
In our workflow, we consider each commit on the mainline branch a release candidate. It means the commit should have gone through the quality gates that we have managed to "shift left". There will be more quality gates later on as the artifact, created from the build, is promoted through environments but we expect the code to be as healthy as we can measure at build time.
master is the traditional name if you have a single mainline branch but we will probably see a more inclusive name surfaces in the coming years.
Feature Branching
To satisfy the parallel development of features, each developer creates a branch from the mainline where they add their changes. Later, these features are introduced back into the mainline by merging (integrating) the feature branches.
Let's play through a scenario where this pattern is applied three times, possibly by multiple developers.
👈 Try it!
Feature branching is a misnomer as this pattern can be used to essentially deliver any changes to the mainline, be it features, fixes, refactors, etc. These branches are considered short-living and should be deleted upon merge.
The branch naming conventions should be decided by the team, based on their ways of working, and used consistently from then on. Some common conventions include feature/*, feat/*, fix/*, refactor/*, etc. Being short-living, the branch names of less significance than the mainline but should be unambiguous during their lifetime.
On Merging Strategies
As a team, we can choose and enforce a merging strategy, to ensure the Git history looks consistent across the repositories.
Git provides a few commands and flags that can be combined to produce a large combination of merging strategies. Here are some of the major ones to keep in mind:
Fast-forward-only strategy mercilessly rejects any incoming changes that are not already sitting on top of its tip. This helps keep the history linear but does force the developers to keep the commits rebased on top of the mainline branch. This could get annoying when multiple developers are racing to merge first so they do not have to be the one rebasing again.
Squash takes all the changes from the feature branch and collapsed them into a single new commit which is placed on top of the mainline branch. Any history from the feature branch is lost and mainline becomes a series of single-commit features. In rare scenarios where developers are branching off each other's feature branches, rather than waiting for the feature branch to be merged into mainline, this strategy will cause more problems.
Explicit merge commit strategy ensures there is always a commit that denotes the merge into the mainline. This makes the Git history more complex with more superfluous commits but also provides as much information about the code history as possible.
On most occasions, a feature branch contains some initial commits and subsequent commits that address peer review comments (unless you practice amending commits on feature branches). These additional commits are not particularly interesting on their own.
Therefore, I tend to prefer the strategies that create a single commit on the mainline. These keep the history clean, each commit corresponding to a feature or a fix. This also means reverting a change is essentially reverting a single commit.
I should note that the above is only relevant for feature branch patterns. I do not recommend squashing commits when merging between mainline branches as that history is significant and should be preserved.
Pull Requests
An extension to feature branching is to add a step, before merging, where the code is peer-reviewed. Most modern source code management systems offer this functionality, typically called pull request or more accurately merge request.
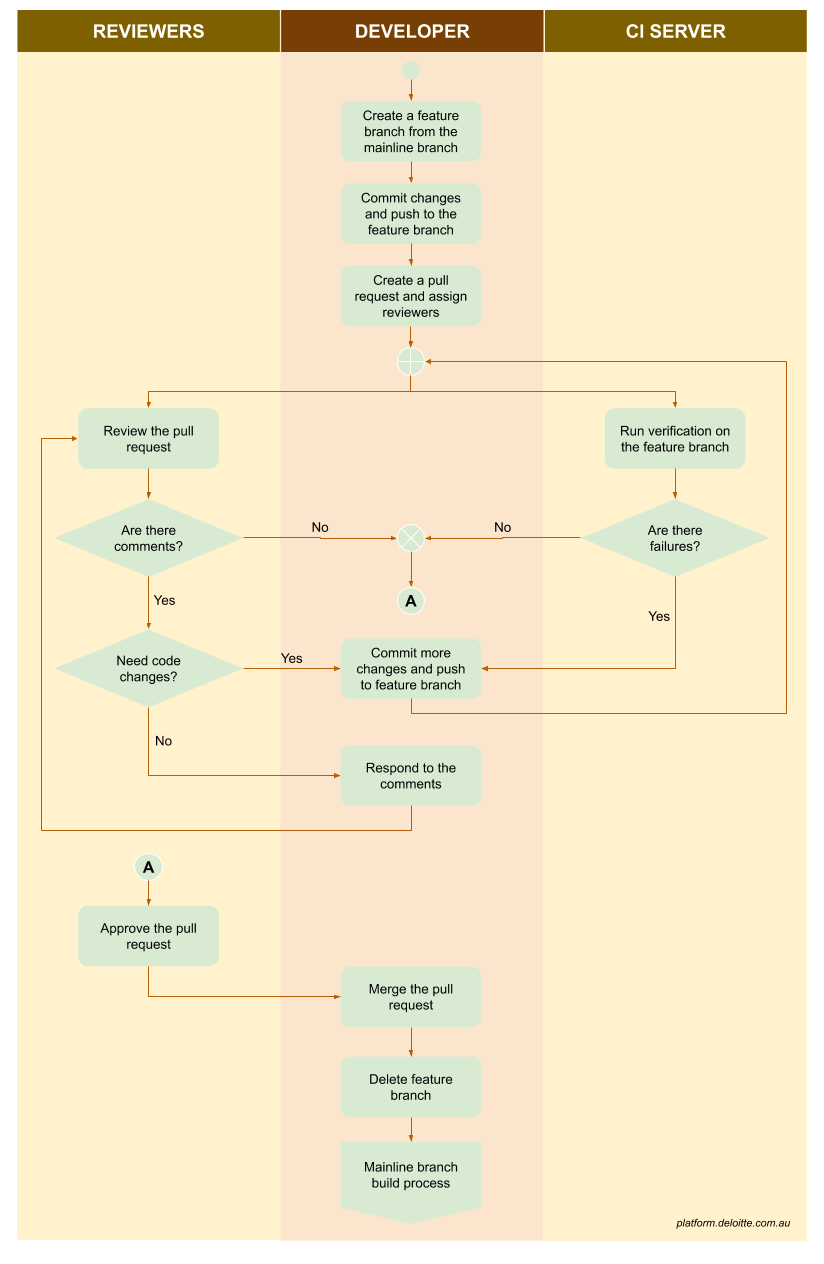
The pull requests should at the minimum check the following:
- The code can be merged, without conflict, into the mainline
- The expected number of reviewers have approved the changes
- A pull request build has occurred successfully, verifying the health of the feature branch
As it is the case whenever you inject humans into a process, pull requests tend to add some friction to the development process, slowing it down. While automated validations have seen significant improvements over the years, there is still no substitute for a human peer review. The overhead is well worth it.
The impact of this delay can be minimised by ensuring pull requests are of manageable size, the team is given enough buffer in their workload to perform reviews and teaching developers to work as asynchronously as possible by moving on to other tasks and come back when the review has been done.
Choosing the reviewers is a bit of an art form as well. Pick too many and each reviewer would feel that their contribution is diminished or not even required. In a small team, where all the developers may be familiar with a codebase, picking reviewers is easier. For much larger teams, assigning a group of developers as the maintainers of a given repository helps to ensure the right people get their eyes on the changes. CODEOWNERS files have become a prominent way to achieve this.
Maintenance Branching
Maintenance branching is a variation on mainline branching to temporarily branch off an older commit, while the mainline is also in development.
Let's imagine that a critical production defect has been found and you check the repository and see there are some new features added to the mainline already. You do not want to bring these new features to production as they have not passed testing yet but you still need to fix the critical issue. In this scenario, you create a temporary mainline branch from the commit currently in production and deliver the fix there. You have just created a maintenance branch.
Another use case would be when the team wants to deliver features for two separate major versions in parallel. The original mainline is used for the current major version while a maintenance branch is created to maintain the previous version as long it is relevant.
As far as branch naming conventions are concerned, it is again something that the team agrees on and then consistently applies across all repos. Some common conventions include release/*, hotfix/*, v1.3.x, etc.
The following walkthrough demonstrates hotfixing production a couple of times while work on the next release also continues. For brevity, feature branches have been omitted here but you can assume each commit is a result of a pull request.
👈 Try it!
You may notice that we have also forward-ported the fixes from v1.3.x branch into the master. The version for this merge commit is determined by all the commits that need to be merged in since branch off. In this case, all commits are fixes, i.e. patch versions, so the resulting merge commit would also be a patch version bump on the mainline commit.
We should keep in mind that maintenance branches are still mainline branches and each of their commits are considered release candidates. Maintenance branches should follow the same rigour as the original mainline branch, going through similar quality gates.
Maintenance branches are normally kept around until they become irrelevant. For example, a production hotfix branch is no longer required once the version in production moves past the hotfix version.
As long as a maintenance branch is active, it introduces additional overhead to that repository as the branches need to be kept in sync so no changes are lost between versions, i.e. no regression.
The team should decide on a pattern for how the maintenance and mainline branches interact and how the changes are back- or forward-ported. For example, you can set a rule such as "Merge changes from the maintenance branch into the mainline, once the version from the maintenance branch has made it past all QA".
Most of these patterns require developer diligence or custom automation created by the team. This is one of the reasons we try to minimise the number of maintenance branches as much as possible.
The good news is that with multi-repos, maintenance branches become a rarer occurrence. I can't tell you how many times I go back to deliver a hotfix to a repository but to realise that mainline branch matches the production so the hotfix becomes a normal fix via a feature branch to the mainline directly.

An Example
We have now discussed all the patterns we need for our branching strategy. Let's put them all together and demonstrate how they can be applied in a complex example.
Let's imagine we are working on the Somethings microservice. Multiple consumers interact with this service for all their Something-related needs.
To support parallel major versions of the service in production, we have created somethings-v1 repository to house the microservice. The deployed application also reuses this naming.
The repository uses a master branch as its mainline branch and semantic versioning. We only use maintenance branches for delivering fixes to existing features so the v<major>.<minor>.x naming convention is used there.
Let's pick up the story in the middle of development. Currently, the microservice sits at v1.2.12 which has been promoted all the way to production.
In the following walkthrough, we demonstrate adding features and fixes, making production hotfixes and even forking a new major version. Again for brevity, I am not showing the feature branches but they are assumed.
👈 Try it!
One interesting aspect of this example is when somethings-v1 is forked into somethings-v2 so we can introduce a breaking change and start working on the v2 versions of the application independently. This does not necessarily have to be a fork and could have been done in the same repo by using v1.x.x and v2.x.x branches (and no master). I find separate repos cleaner as it makes it clear that these are two different applications now that can be run in parallel in production. At some point when all the consumers have moved to the v2 interface, we can simply archive the v1 repository. Using a fork also preserves all the Git history back to very first commit.
I should mention that this is a somewhat contrived example. Often due to high engineering cost of maintaining multiple services, the older version of the application normally goes into maintenance mode and should only receive fixes and no new features. But the branching strategy does not restrict you either way.
This is something to keep in mind. The branching strategies can provide some guardrails to the process but they do not replace good software engineering practices or even plain common-sense.
I have had a variation of the question "Your process doesn't stop me from doing XXXX (something really stupid)" more than I would have hoped in my career. I normally try to explain, calmly, that the process can try to cater for that (really stupid thing) but that would make it more cumbersome for everyone else that does exercise common-sense, just to plug a hole no one should really fall into. Let's give the developers some credit!
On Gitflow and GitHub Flow
If you have been around the traps, there is nothing particularly earth-shattering in the workflow we have come up with. It stands on the shoulders of giants like Gitflow and GitHub Flow and tweaks them to come up with an optimal configuration that specifically meets our requirements.
Gitflow is great if you want to put very little thought into your branching strategy upfront while not painting yourself into any corners for any unforeseen future scenarios. But this comes at a cost as Gitflow is heavy on ceremony, which is exasperated by those ceremonies repeating across all your repos. Gitflow tends to give the same weight and importance to every scenario, regardless of how frequent and rare they are. Painting feature development and rare hotfixes with the same brush results in heavy processes whichever you look.
Particularly, I am not fond of how many long-living branches are kicking around in a given Gitflow repo and with many repos, it is a full-time job to keep them in sync. Furthermore, develop-master branch setup is redundant once you consider each build into the mainline a release candidate. Not to mention, merging to master creates a new binary, different from the one tested from develop branch, which breaks our "build once, deploy many times" practice.
GitHub Flow overcorrected for the shortcomings of Gitflow by keeping things very light and simple. However, that does mean that it barely covers the requirements that we set at the outset.
Our workflow tries to strike a balance between the featureful, heaviness of Gitflow and the basic, lightness of GitHub flow.
On Feature Toggles
I should also make a mention of Feature toggles. Given our emphasis on interface versioning, feature toggles fit oddly into our setup.
Often when you want to hold off a feature, you simply do not deploy it to production but with the realities of software development, that feature may not be the latest one on the mainline. You could simply revert that commit and create a new feature to deploy but this does seem wasteful, especially in organisations with more arduous paths to production.
Feature toggles come in handy in these scenarios but now the version of the application is no longer the source of truth for the changes. We have bumped the feature version but it is turned off so the application currently running is no different from the one without the feature.
While you incur additional testing overhead for additional paths in the code, feature toggles are still a valuable tool in your toolkit and our workflow does not in one way or another promote or prevent their use.

Evaluating the Workflow
Now for the moment of truth! Does our workflow meet the requirements that we laid out at the start of this post?
|
Requirement
|
Met
|
|
Git
|
✅
|
|
Microservices architecture
|
✅
|
|
Multiple repos
|
✅
|
|
Target containerised platforms
|
✅
|
|
Commercial setting
|
✅
|
|
Smaller, more frequent releases
|
✅
|
|
Parallel feature development
|
✅ Feature branching pattern
|
|
Hotfix development
|
✅ Maintenance branching pattern
|
|
Parallel release development
|
✅ Maintenance branching pattern
|
|
Parallel major versions in production
|
✅ Maintenance branching pattern and one repo per major version
|
How about the best practices?
|
Best Practice
|
Met
|
|
Intuitive and unambiguous
|
A few patterns with predictable procedures but the success of this is for the team to decide after exercising the workflow for a while
|
|
Reduce ceremonies
|
Mainline branching and only create maintenance branches when absolutely necessary
|
|
Minimise long-living branches
|
One mainline branch, with exceptional maintenance branches only when required
|
|
Build in quality
|
Pull requests, automated test and build, peer reviews, etc.
|
|
Build binaries once
|
Run builds on mainline (and maintenance) branches and give each an immutable version as a release candidate
|
I think we have done pretty well here, even if I say so myself.
I should note that even if this process looks good today, it may not tomorrow. Once in a while, I meet a development team with the irrational fear that what if we don't get this right up front? This is not a big deal! It would be hubris to assume one can come up with a process that will still be optimal while around it, the team and the industry evolves and improves rapidly.
My advice is not to get too hung-up on finding the perfect process. Find a process that works for your team at that point in time. Nothing is set in stone and expect that you will continuously improve the process as things change.
Best of luck!
Icons made by Freepik from Flaticon.