
Recently we’ve been writing quite a few ‘bulk’ APIs - where consumers don’t want a single resource, or a screenful of search results but instead need (close to) the entire record set. In this blog we discuss several features of the Mule ESB platform that make is easy to design and implement bulk APIs over a variety of back-end technologies.
Big-ish Data
When your API deals with small messages (i.e. single resource or a screen’s worth of search results) it is trivial to pull into memory all the code and data you need to handle an API call. On the other end of the spectrum is up- or downloading the gigabyte- or terabyte-sized datasets common to web-scale analytics workloads - true ‘big data’ problems.
In a ‘bulk’ API, data size is somewhere in the middle. Not so large as to require a dedicated mass data loading channel, but large enough the we need to design and code carefully to avoid pulling our full dataset into memory. Let’s call it a ‘big-ish data’ problem. The key concept to embrace is streaming at all stages in your code, so you can process your large dataset a portion at a time, retrieving input data on demand and sending output as soon as it is ready.
This is especially true if there is data transformation involved since naive coding might result in you holding multiple copies of your entire dataset in memory while the transformation is in process.
Designing APIs with RAML
Restful Application Markup Language (RAML) is an industry standard for developing APIs in a contract-first style. Mule has excellent support for RAML through its APIKit module.
A RAML API definition is a YAML document that describes REST resources, methods, inputs and outputs. A very helpful feature is the ability to externalise schemas and sample messages into separate files and then reference them in the RAML. Your sample messages can then form the core of your development workflow:
- Samples become stub responses in a skeleton API Mule implementation using APIKit code generation.
- Samples become metadata to define the input/output structures in your data transformations.
- Samples become instant test data to write unit tests using Mule TCK or MUnit.
For an excellent in-depth tour of RAML, see this tutorial: Designing an Event Log API with RAML.
The secret to designing effective Bulk APIs with RAML is this:
There is no spoon.
A Bulk API is just an API. Nothing about the definition of your API contract changes just because your resource representations will be large. This is the beauty of contract-first development: it stops implementation details leaking into your interface.
Why CSV is (still) cool
REST APIs tend to deal with internet-standard media types: XML, JSON etc. While it’s possible to write a Bulk API for many of these formats their tree structure makes it more difficult to stream data, particularly through a transformation step.
A great media type choice in these cases is the CSV (Comma Separated Values) format. CSV is often maligned as old-fashioned or overlooked altogether, however it has several qualities that make it ideal for large datasets:
- CSV is self-describing - column names are included in a header row.
- CSV is flat - no need to keep track of what XML tags to close or how deep in your JSON structure you’ve gone. Each new record can simply be appended as a new line to the end of the previous output.
- CSV is simple - you do not need any specialised libraries to read or write CSV data.
- CSV is human-readable - easy to monitor and troubleshoot.
CSV is by no means perfect. There is no support for datatypes (everything is a string) and the IETF standard is recent and not universally supported. If your data is a big long table though, CSV is worth consideration.
A little bit of Lambda goes a long, long way
As mentioned before, the tricky part of Bulk APIs is the implementation. You need the right patterns and the right technologies to retrieve, transform and publish data in a streaming fashion. It becomes even trickier when you need to compose those steps into a single flow and maintain the streaming property.
To tackle this we can adopt some concepts from Functional Programming. Let’s imagine our Mule flow as a function. Normally this function maps a request to a response directly:
flow = (request) -> response
Visually the Mule flow would look something like this (the back-end system in this example is a database query but it could be any Mule endpoint that supports streaming or iteration):
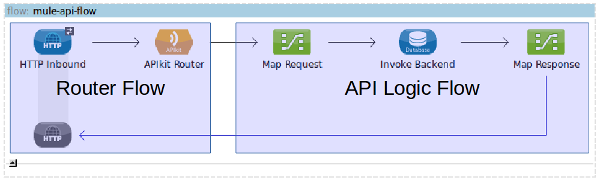
Note: Mule APIKit places the API router and the logic of each operation in separate flows. I’ve combined these into a single flow because it makes it easier to visualise.
In a Bulk API we want to change this so that the flow returns a function that outputs the response to an output stream:
flow = (request) -> ((outputstream) -> nil)
The response half of the flow logic is no longer executed immediately. Instead it becomes the logic of an anonymous function / lambda / callback. Mule invokes the callback function once it has begun writing the HTTP response to the consumer (and so actually has an output stream to pass in to the callback as the input parameter).
Visually the Mule flow remains unchanged, but I’ve highlighted the part of the flow that becomes the streaming callback logic:
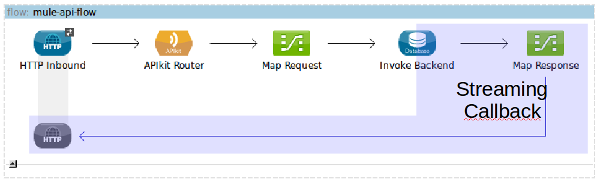
When Mule invokes the callback function, the following takes place:
- Mule obtains a
java.io.OutputStreamobject representing the HTTP response channel and invokes the callback with this stream as a parameter. - Callback function reads a small amount of data from the back-end response stream/iterator and buffers it.
- Callback function transforms the buffered back-end data into the required response format.
- Callback function writes the response bytes to the output stream.
- The buffered back-end data and any temporary objects created during transformation are no longer used and can be garbage-collected by the JVM to free up memory.
- Steps 2-5 are repeated until all fragments of the response have been written.
When properly implemented, your callback is not only streaming but lazy. Just enough data is read from the back-end response stream just in time to output the next fragment of the response.
Mule specifies its own interface org.mule.api.transport.OutputHandler that your flow logic must implement in order to be treated as a streaming callback. That is: the MuleMessage payload at the end of the flow needs to be an instance of this interface. The interface code is reproduced below:
| /* | |
| * Copyright (c) MuleSoft, Inc. All rights reserved. http://www.mulesoft.com | |
| * The software in this package is published under the terms of the CPAL v1.0 | |
| * license, a copy of which has been included with this distribution in the | |
| * LICENSE.txt file. | |
| */ | |
| package org.mule.api.transport; | |
| import org.mule.api.MuleEvent; | |
| import java.io.IOException; | |
| import java.io.OutputStream; | |
| /** | |
| * The OutputHandler is a strategy class that is used to defer the writing of the message payload | |
| * until there is a stream available to write it to. | |
| */ | |
| public interface OutputHandler | |
| { | |
| /** | |
| * Write the event payload to the stream. Depending on the underlying transport, | |
| * attachements and message properties may be written to the stream here too. | |
| * | |
| * @param event the current event | |
| * @param out the output stream to write to | |
| * @throws IOException in case of error | |
| */ | |
| void write(MuleEvent event, OutputStream out) throws IOException; | |
| } |
There is nothing stopping you from hand-coding an implementation of the OutputHandlerclass. However Mule provides several features that make creating such callbacks, as well as composing them together, much easier. Let’s take a look at a few of these:
Streaming database queries
The Database connector was introduced in Mule 3.5, replacing the older JDBC transport. It supports a streaming mode built on the underlying java.sql.ResultSet cursor. Enabling this behaviour is as simple as checking the ‘streaming’ checkbox on the DB query processor.
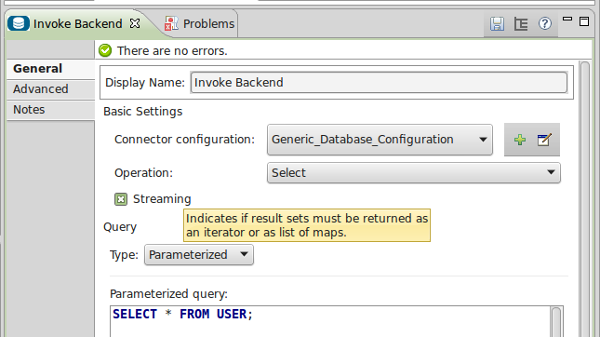
With streaming disabled, the DB query processor returns a List of Maps. With streaming enabled, the output payload becomes an Iterator of Maps. when the next() method is called on the iterator, the DB module reads a single row from the underlying ResultSet and converts it into a Map[column name -> column value].
Streaming HTTP calls
Streaming the response from an HTTP back-end service is beautifully simple - you don’t need to do anything. By default the output from a Mule <http:outbound-endpoint> is already a java.util.InputStream making it ideal to feed into a streaming transformation step.
Anypoint Connector Auto-Paging
Many 3rd party APIs implement a ‘paging’ mechanism, where consumers must make multiple API calls with some kind of ‘page number’ or ‘record offset’ parameter in order to fully retrieve a large result set.
The MuleSoft Anypoint Connector DevKit is a simple yet powerful SDK for generating custom Mule connectors from annotated Java classes. This framework provides special support for interacting with paging APIs. Your DevKit processor method returns a ‘paging delegate’ object that keeps track of the ‘next page’ and, when invoked, queries the back-end and returns each page as a java.util.List of objects. DevKit flattens this ‘lazy list’ of pages into a single continuous iterator object that can be fed into subsequent transformation steps. See the DevKit Query Pagination documentation for more details.
Streaming transforms with AnyPoint DataMapper
AnyPoint DataMapper is a drag-and-drop data mapping and transformation tool provided with Mule Enterprise Edition deployments. It has its roots in the Open Source CloverETL library. DataMapper can transform to and from a range of common data formats and can operate in streaming mode (a reflection of its ETL heritage). DataMapper can stream transformations of structured data like XML and JSON.
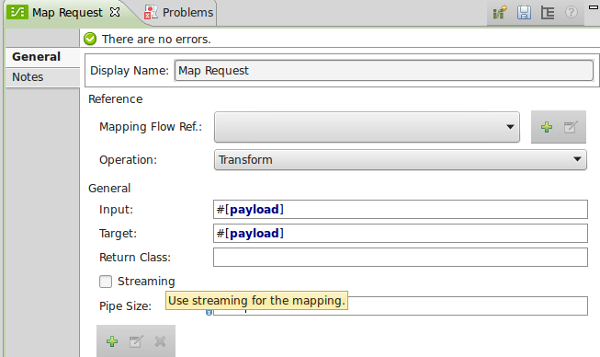
As with the DB connector, enabling streaming in DataMapper is as simple as checking a box. Additionally you can specify the streaming buffer size (in bytes). Tuning this value may improve performance if your individual records are very small or very large. In streaming mode, the output payload of the DataMapper step will be a OutputHandler instance.
Streaming transforms with Groovy
There are a few edge cases where writing a streaming DataMapper transform is not possible. In these situations it is possible to write transformations as Groovy scripts using Groovy’s ‘Builder’ classes. For XML, Groovy’s XMLSlurper and StreamingMarkupBuilderclasses support lazy parsing and streaming transformation. (For more on coding transformations in groovy see our articles on ‘Data Mapping with Groovy’ part 1 and part 2)
There is no OutputHandler magic here. The Groovy scripting approach requires you to actually code an implementation of the streaming callback. Luckily groovy syntax makes this quite streamlined:
| import org.mule.api.transport.OutputHandler | |
| // store the current payload at the time the script is invoked | |
| // (i.e. the back-end response stream/iterator) | |
| def itr = payload; | |
| // return a Groovy closure / lambda | |
| return {evt, out -> | |
| // define a stream XML builder object | |
| def xml = new groovy.xml.StreamingMarkupBuilder(); | |
| // construct the builder function | |
| def xmlClosure = { | |
| mkp.declareNamespace(ns0: "http://mycomany.com/schema/account/v1/xsd") | |
| is.accountList { // XML root element | |
| itr.each { _acnt -> // lazily iterate over the back-end response records | |
| account { // XML record element | |
| systemId(_acnt.accountId) | |
| // map other fields in here as necessary | |
| // ... | |
| } | |
| } | |
| } | |
| } | |
| // write the resulting XML directly to the output stream provided by Mule as a parameter | |
| out << xml.bind(xmlClosure); | |
| } as OutputHandler // Groovy way to implement a Java interface with a single method |
Content-Type is crucial
We faced some issues with our Mule APIKit applications not streaming despite very careful coding. Eventually we tracked the problem down to the Mule APIKit router component. APIKit is extremely strict about correct content type headers. Not only must the MuleMessage payload be stream-able but the Content-Type outbound property must align with the type specified in your RAML file. If the content type does not match (or you forgot to specify it), the APIKit router calls Mule’s automatic transformation logic which will:
- Write your carefully coded streaming transformation into an gigantic in-memory byte array.
- Helpfully set the ‘Content-Type’ outbound property.
- Write the gigantic in-memory byte array out the the consumer.
Obviously, this is the exact opposite of what we’re trying to achieve, so always remember to set your Content-Type…
Summary
Hopefully this article has given you the resources to design and build your own Bulk APIs on the Mule ESB platform. Writing lazy streaming code is never easy, but if you understand the concepts behind what you’re trying to achieve Mule’s features can make your life a lot easier.